Datensätze (Data Sets)¶
Übersicht
Für die Dokumentation der Datensätze werden die „Master“(AIP)-Datensätze (siehe Zwiebelmodell) genutzt. Diese Datensätze sind die größte mögliche Vereinheitlichung eines Datensatzes, also keine Teilpopulation oder Teilmenge von Variablen eines Datensatz. Datensätze die sich als Teilmenge eines „Master“-Datensatzes abbilden lassen werden über die Subdatensätzen (SubDataSets) dokumentiert. Mit Subdatensätzen sind solche gemeint, die Sie nach einer Anonymisierung Ihrer Daten erhalten. Sie können mehrere Stufen der Anonymisierung verwenden, wobei jede Stufe einen eigenen Zugangsweg zu den anonymisierten Daten mit sich bringt. Für jeden Zugangsweg wird dann ein eigener Subdatensatz erstellt.
Mit den Informationen über die Datensätze, welche Sie aus den Daten Ihres Datenpakets erstellt haben, wird für jeden dieser Datensätze folgende Übersicht im MDM angezeigt:
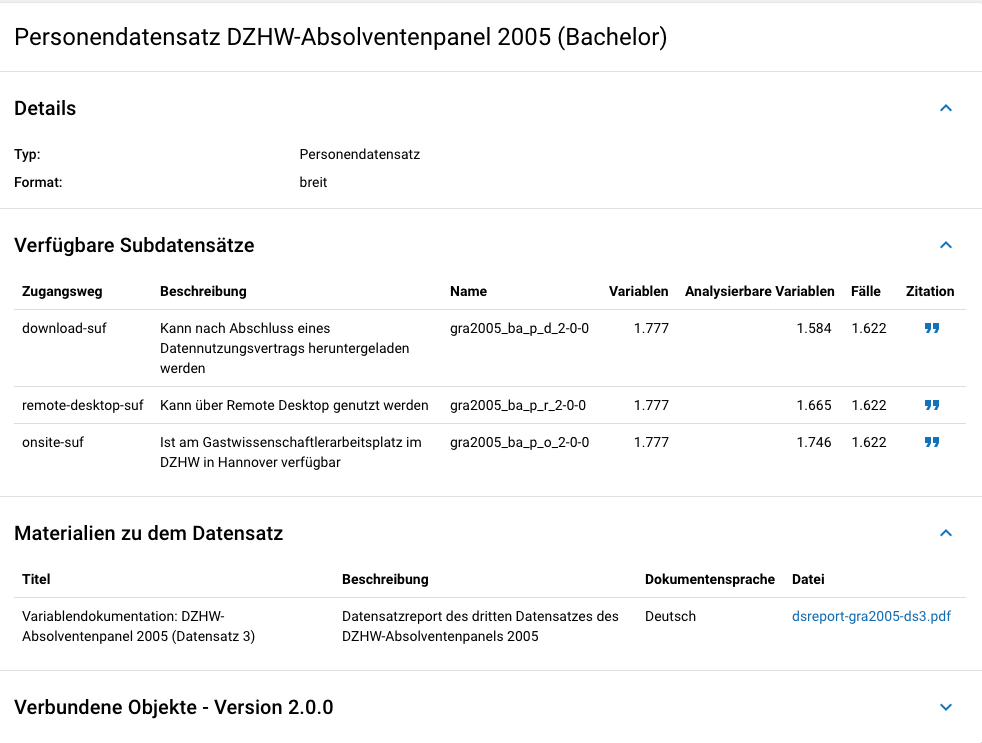
Abb. 29 Datensatzübersicht im MDM am Beispiel des Personendatensatzes (Bachelor) im Absolventenpanel 2005
Eingabemaske
Datensätze lassen sich per Eingabemaske anlegen und editieren. Hierfür muss man entweder über das Projektcockpit gehen, oder in der Suche auf
den Reiter Datensätze klicken (mdm-ebenen), anschließend auf das Plussymbol (Abb. 30) in der unteren rechten Ecke klicken. Anschließend öffnet sich die Eingabemaske (siehe Abb. 31).
Abb. 30 Neuen Datensatz hinzufügen.
Die mit * markierten Felder sind verpflichtend. Die verknüpften Erhebungen werden nach einem Klick in das Feld „Erhebungen“ automatisch vorgeschlagen und können per Klick ausgewählt werden. Im Anschluss werden die Subdatensätze per Eingabemaske auf der selben Seite eingegeben. Weitere Subdatensätze können per Klick auf das Plussymbol hinzugefügt werden. Nachdem gespeichert wurde, lassen sich weitere Materialien zum Datensatz hinzufügen.
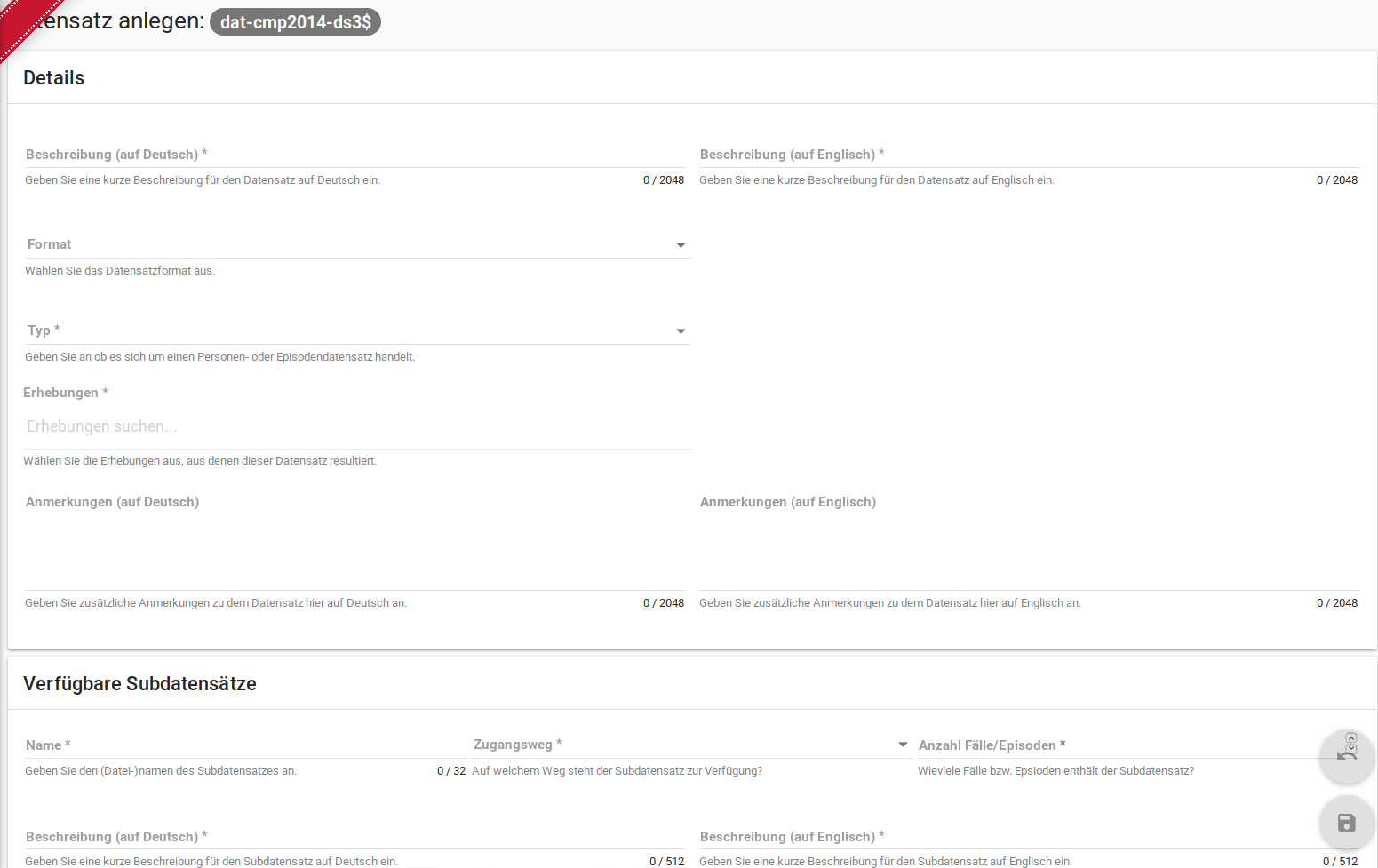
Abb. 31 Eingabemaske der Datensatzebene.