Fragen (questions) [1]¶
Übersicht
Zu den einzelnen Fragen eines Instruments (sprich: Fragebogen) können Sie Informationen in das MDM übermitteln, in welchem dann für jede Frage folgende Übersichtsseite erstellt wird:
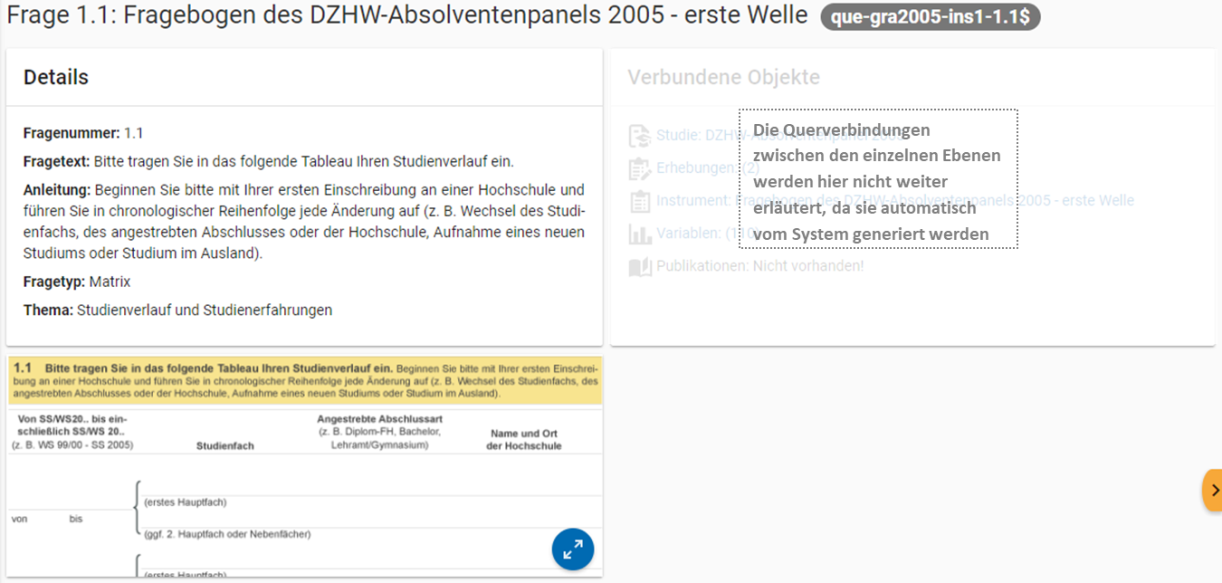
Abb. 47 Fragenübersicht im MDM am Beispiel der Frage 1.1 des Fragebogens der ersten Welle im Absolventenpanel 2005
Auf dieser Ebene werden Informationen über alle Fragen für jedes einzelne Erhebungsinstrument einer Studie abgeben. Der Einspeisungsprozess dieser Informationen hängt vom Typ des Erhebungsinstrumentes ab. Während Daten aus Onlinebefragungen, die mit ZOFAR, dem Datenerhebungssystem den DZHW, durchgeführt wurden, direkt aus dem System heraus extrahiert werden (siehe Questions (ZOFAR)), müssen Daten aus allen anderweitig durchgeführten Befragungen – sowohl andere Onlinebefragungen als auch PAPI-Befragungen – manuell erfasst werden (siehe Questions (manuell)). Im Folgenden werden beide Vorgehensweisen schrittweise beschrieben.
Fragestruktur¶
Fragen sind gekennzeichnet durch einen einleitenden/übergreifenden Fragetext, sowie eine „natürliche“ sichtbare Abgrenzung gegenüber anderer Fragen und eine meist „erkennbare“ Nummerierung. Es wird zwischen fünf Fragetypen differenziert:
- Single Choice: Auf die Frage kann nur mit einer Antwortmöglichkeit geantwortet werden (z.B. Einfachauswahl aus mehren Antwortmöglichkeiten oder Angabe eines numerischen Wertes).
- Mehrfachnennung: Für die Frage gibt es eine Auswahl an Antwortmöglichkeiten bei denen eine oder mehre ausgewählt werden können.
- Itembatterie: Besitzt überleitenden Fragetext, welche jeweils weitere Items mit den gleichen Antwortmöglichkeiten besitzen.
- Matrix: Ist ein komplexer Fragetyp in dem viele Unterfragen geschachtelt werden können und die nicht durch die anderen Fragetypen abgedeckt werden (z.B. Tableaufragen des Absolventenpanels ).
- Undocumented: Die „Restkategorie“, sollte die Frage nicht mit einem der oben genannten Fragetypen abzubilden sein.
Questions (manuell)¶
Um json Dateien zu erzeugen muss zuerst einmal eine Exceltabelle ausgefüllt werden. Die Exceltabelle hat die beiden Tabellenblätter questions und images. Spaltennamen und Ausfüllanweisungen sind im nächsten Abschnitt zu finden.
Zusätzlich können zu jeder Frage ein oder mehrere Bilder vorhanden sein (im Gegensatz zu früher nicht mehr verpflichtend). Es ist aber zu beachten, dass im Moment die R-Skripte noch nicht dahingehend aktualisiert wurden. Wie Fragebilder aus Ragtime-Dateien extrahiert werden können, wird erklärt: Bilderfassung aus RagTime Eine Anleitung zum Ausschneiden von Bildern aus pdf Dateien ist hier zu finden Bilderfassung aus PDF Dateien.
Excel-Tabelle
Um Metadaten auf der Fragenebene in manueller Weise zu erfassen, müssen Sie die Excel-Datei questions.xlsx ausfüllen, welche die beiden Tabellenblätter questions und images beinhaltet. Sie können alle Fragen aus allen Erhebungsinstrumenten in einer einzigen Exceltabelle erfassen:
Tabelle 3: Ausfüllanweisungen für die Excel-Tabelle „questions“
| Tabellenblatt 1: questions | ||
|---|---|---|
| Es können mehrere Fragen eingetragen werden (= mehrere Zeilen möglich, eine Frage pro Zeile) | ||
| Spaltenüberschrift | Muss ich das ausfüllen? | Was muss ich eintragen? |
| indexInInstrument | Ja | Nummer der Frage im Fragebogen, nach der die Reihenfolge festgelegt wird (ganzzahlig) |
| questionNumber | Ja | Fragenummer, idealerweise selbsterklärend aus Instrument (z. B. 1.1). Format: 0-9, a-z, Umlaute, ß, ., - |
| instrumentNumber | Ja | Nummer des Instruments |
| questionsText.de/en | Ja | „Übergreifender“ Fragetext, bei Itembatterien oder komplexen Fragen der einleitende Fragetext. Bei „einfachen“ Fragetypen der komplette Fragetext. |
| instruction.de/en | Nein | wenn vorhanden, Anweisungstext der Frage |
| introduction.de/en | Nein | wenn vorhanden, Einleitungstext der Frage |
| type.de/en | Ja | de: „Einfachnennung“, „Offen“, „Mehrfachnennung“, „Itembatterie“ oder „Matrix“ (eine Anleitung zur Einteilung der verschiedenen Fragetypen kann unter https://github.com/dzhw/metadatamanagement/files/1421895/Anleitung_Vergabe_Fragetypen.docx gefunden werden) en: „Single Choice“, „Open“, „Multiple Choice“, „Item Set“ or „Grid“. |
| topic.de/en | Nein | Themenblock, in dem die Frage im Instrument eingeordnet ist (idealerweise direkt aus Instrument entnehmbar) |
| successorNumbers | Nein | Fragenummern der nachfolgenden Frage(n) (Angabe in einer Zeile durch Komma getrennt) |
| technicalRepresentation.type | x* | Herkunft des Codeschnipsels (z. B. „ZOFAR-Question Markup Language“) |
| technicalRepresentati on.language | x* | Technische Sprache des Codeschnipsels (z. B. XML) |
| technicalRepresentation.source | x* | Codeschnipsel, um Frage technisch abbilden zu können (z. B. QML-Schnipsel) |
| additionalQuestionText.de/.en | Nein | Weitere Ausführungen der Frage, die nicht im Fragetext stehen, wie z. B. der Itemtext (bei Itembatterien) oder Antworttext (bei Mehrfachnennungen). Aktuell ist diese Information für den Nutzenden des MDM nicht sichtbar, sondern wird nur bei einer Volltextsuche berücksichtigt. |
| annotations.de/en | Nein | Anmerkungen zur Frage |
x* = nur, wenn technicalRepresentation vorhanden (wird dann automatisch von ZOFAR geliefert)
Tabellenblatt 2 ist nur auszufüllen falls es Bilder zu den Fragen gibt.
| Tabellenblatt 2: images | ||
|---|---|---|
| Es können mehrere Bilder eingetragen werden (= mehrere Zeilen möglich, ein Bild pro Zeile) | ||
| Spaltenüberschrift | Muss ich dasausfüllen? | Was muss icheintragen? |
| fileName | Ja | Dateiname des Bildes (z.B. „1.1_1.png“) |
| questionNumber | Ja | Dem Bild zugeordnete Fragenummer |
| instrumentNumber | Ja | Nummer des zum Bild gehörenden Instruments |
| language | Ja | Sprache des Bildes Bitte verwenden Sie eine Abkürzung nach ISO 639-1_: z. B. „de“, „en“ |
| indexInQuestion | Ja | Auf das wievielte Bild der Frage bezieht sich die Zeile? (Liegt pro Frage nur ein Bild vor, steht hier immer 1) |
Mit dem zweiten Tabellenblatt images erfassen Sie Informationen zu den Fragebildern, welche Sie für jede Frage mit hochladen können. Falls Bilder vorhanden sind, müssen diese im Png Format vorliegen. Die Fragebilder können z.B. mit Ragtime extrahiert werden, sofern der Fragebogen auch mit Ragtime erstellt wurde. Ansonsten lassen sich die Fragebilder auch aus einer PDF-Datei erstellen. [2] Anleitung für beiden Varianten finden Sie unter Bilderfassung aus RagTime und Bilderfassung aus PDF Dateien.
Die fertig ausgefüllte Excel-Datei sowie ggfs. die Bilder zu den Fragen speichern Sie dann in dem Ordner, den das FDZ für Sie vorbereitet hat. Das FDZ greift daraufhin auf die Dateien zu, verarbeitet sie weiter und lädt die Metadaten für die Fragenebene dann selbst ins MDM.
Generierung der json Dateien mit R¶
Doku befindet sich im Aufbau und ist nur für FDZ-MitarbeiterInnen relevant.
Momentan liegen die Question-Exceldateien der Projekte, sowie die Skripte
zur Erzeugung der json Dateien im Verzeichnis
\\faust\Abt4\FDZ\Querschnittsaufgaben\Metadaten\Erzeugen.
Der Aufbau ist wie folgt:
|-- Projekte
|-- projectName
|-- questions
|-- out
|-- projectName.xlsx
|-- Skripte
|-- question-generation.R
|-- sort-images.R
|-- R
|-- question-generation_main.R
|-- utils
|-- question-generation_functions.R
Um json Dateien für ein neues Projekt zu erzeugen, muss zuerst ein
Projektordner angelegt werden. Außerdem muss die Question-Exceltabelle des
Projektes ausgefüllt werden (z.B. projectName.xlsx mit den beiden
Tabellenblätter questions und images). Außerdem muss der Ordner out angelegt
werden. Danach question-generation.R öffnen und bei project den Projektnamen
anpassen, z.B. project <- "gra2005". Das Skript z.B. mit Strg+a ->
Strg+Enter ausführen. Im Ordner out sind nun die json Dateien für den
Import in der vorgegebenen Ordnerstruktur zu finden.
Einsortierung der Bilder in die Ordnerstruktur
Nun müssen die Bilder noch in die Ordnerstruktur eingepflegt werden. Dafür kann das R-Skript sort-images.R verwendet werden. Die pngs zu den Fragen (es können auch mehrere pngs zu einer Frage vorliegen) und das Tabellenblatt images der Exceltabelle werden dafür benötigt. Nähere Erklärungen zur Sortierung der Bilder sind im R-Skript selbst zu finden.
Die fertigen jsons und Bilder können nun zu Github ins jeweilige
$projectname-metadata-repository kopiert werden.
Questions (Zofar)¶
Bei Onlinebefragungen mit Zofar können die Metadaten für Fragen automatisch extrahiert werden (.jsons + .pngs).
Der Prozess befindet sich gerade im Aufbau…
| [1] | Metadaten auf Fragenebene sind erst ab der 2. Dokumentationsstufe gefordert. Die Erläuterungen zu den drei verschiedenen Dokumentationsstandards finden Sie in den Dokumenten „Anforderungen an Daten und Dokumentation im FDZ des DZHW“. |
| [2] | Bitte beachten Sie, die dokumenteigenen Metadaten der PDF-Dateien vorab zu löschen (vgl. Anhänge). |