Variablen (variables) [1]¶
Übersicht
Anhand der Informationen, die Sie auf Ebene der Variablen abgeben, wird für jede Variable eine Übersichtsseite im MDM erstellt:
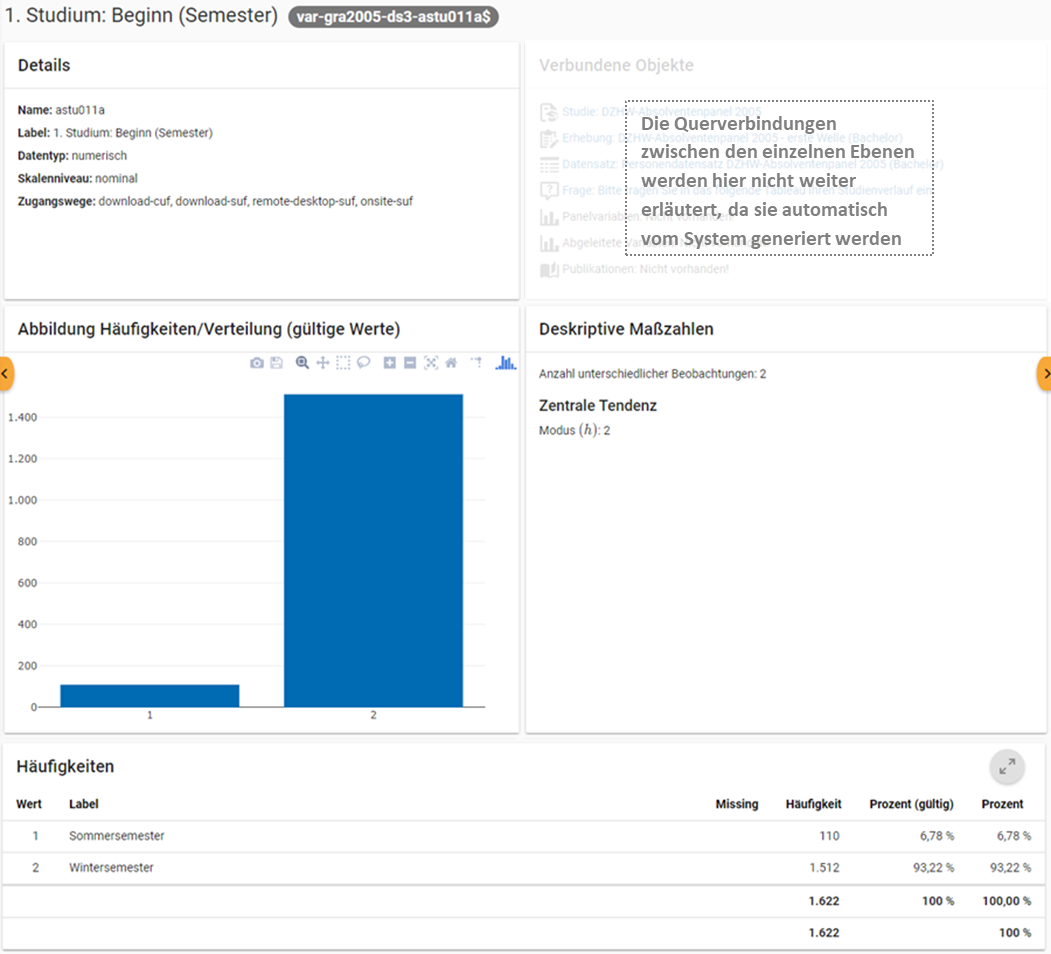
Abb. 48 Variablenübersicht im MDM am Beispiel der Variable „1. Studium: Beginn (Semester)“ im Absolventenpanel 2005, erste Welle (BA)
Die Erstellung der Variablenebene beinhaltet einerseits recht viel Aufwand, da für jeden Datensatz eine eigene Excel-Tabelle mit Informationen zu allen Variablen geliefert werden muss. Viele Informationen müssen manuell eingetragen werden, einige können – sofern die Befragung über Zofar stattgefunden hat – auch direkt aus Zofar (das Onlinebefragungstool des DZHW) extrahiert werden oder sogar aus der Excel-Tabelle der Frageebene importiert werden.
Die Variablenebene ist andererseits sehr wertvoll im Hinblick auf die Nachnutzbarkeit der Forschungsdaten. Wenn Metadaten auf dieser Ebene vorhanden sind, können die dazugehörigen Daten auch aus inhaltlicher Sicht umfassend durchsucht werden, sodass das Analysepotential auch für sehr spezielle Fragestellungen direkt sichtbar wird.
Für die Darstellung der Metadatenaufnahme auf Variablenebene gilt es noch folgende Dinge zu beachten:
- Wenn Sie mehrere Datensätze liefern: Es darf kein Variablenname doppelt vorkommen.
- Missings müssen global definiert sein, d. h. sie müssen für alle Variablen eines Datensatzes gelten.
Excel-Tabelle
Ausfüllen müssen Sie je nach Anzahl der Datensätze mindestens eine Excel-Datei mit dem Namen vimport_ds***Nr.*.xlsx, wobei die „Nr.“ im Dateinamen der Nummer des dazugehörigen Datensatzes entsprechen muss, d. h. die Variablen des Datensatzes mit der Nummer 1 muss vimport_ds1.xlsx heißen usw. Die Datei enthält die beiden Tabellenblätter variables und relatedQuestions.
Tabelle 5: Ausfüllanweisungen für die Excel-Tabelle „vimport_ds*Nr*.“
| Tabellenblatt 1: variables | ||
|---|---|---|
| Es können mehrere Variablen eingetragen werden (= mehrere Zeilen möglich, eine Variable pro Zeile) | ||
| Spaltenüberschrift | Muss ich das ausfüllen? | Was muss ich eintragen? |
| name | Ja | Variablenname |
| surveyNumbers | Ja* | Angabe aller der Variablen zugehörigen Erhebungsnummern (in einer Zelle durch Komma getrennt) |
| scaleLevel.de/.en | Ja | de: „nominal“, „ordinal“, „intervall“ oder „verhältnis“ en: „nominal“, „ordinal“, „intervall“ or „ratio“ |
| panelIdentifier | Nein* | Identifier zur eindeutigen Zuordnung von Panelvariablen. Präfix muss aus der Projekt-ID + Nummer des Datensatzes bestehen (Beispiel: gra2005-ds1), der hintere Teil des Identifiers ist beliebig wählbar, muss aber eindeutig sein. Beispiel: Sind die Variablen astu01a und bstu01a aus dem 1. Datensatz des Projekts gra2005 Panelvariablen, so könnte der Identifier gra2005-ds1-stu01a lauten. |
| annotations.de/en | Nein | Anmerkungen zur Variablen |
| accessWays | Ja* | Mögliche Zugangswege: Download-CUF, Download-SUF, Remote-Desktop-SUF, On-Site-SUF. Bei mehreren Zugangswegen sind den verschiedenen Zugangswegen entsprechend Spalten vorhanden, die mit „nicht verfügbar im …“ überschrieben sind. Für jede Variable muss dann ein „x“ gesetzt werden, wenn diese über den jeweiligen Zugangsweg nicht vorhanden ist. |
| filterDetails.description.de/.en | Nein | Verbalisierte Beschreibung des Variablenfilters |
| filterDetails.expression [2] | Ja, wenn Filter vorhanden | Regel, die in der angegebenen „Sprache“ (.expressionLanguage) beschreibt, welche Teilpopulation zu dieser Variable hin gefiltert wurde (auch verschachtelte Filterführung wird beachtet (PAPI)) |
| filterDetails.expressionLanguage [2] | Ja, wenn Filter vorhanden | Sprache des Filterausdrucks: „Stata“ |
| generationDetails.description.de/.en | Nein | Beschreibung, wie die Variable erzeugt wurde, wenn sie nicht direkt aus dem Fragebogen abgelesen werden kann (Beispiel, siehe Abschnitt „Generierungsdetails“) |
| generationDetails.rule | Ja, wenn Variable generiert | Regel, die in der angegebenen „Sprache“ (.ruleExpressionLangu age) beschreibt, wie die Variable erzeugt wurde (Beispiel, siehe Abschnitt „Generierungsregel (Stata)“) |
| generationDetails.ruleExpressionLanguage | Ja, wenn Variable generiert | Sprache der Erzeugungsregel: „Stata“ oder „R“ |
| derivedVariablesIdentifier | Nein* | Identifier zur eindeutigen Zuordnung von abgeleiteten Variablen. Präfix muss aus der Projekt-ID + Nummer des Datensatzes bestehen (Beispiel: gra2005-ds1), der hintere Teil des Identifiers ist frei wählbar, muss aber eindeutig sein. Beispiel: Wurde die Variable astu01a_g1 aus astu01a abgeleitet, so könnte der Identifier gra2005-ds1-astu lauten. Wichtig: Alle Variablen, aus denen die abgeleitete Variable entstanden ist, müssen berücksichtigt werden (sowohl aufwärts als auch abwärts). Beispiel: Von der tatsächlichen Hochschule wird sowohl der Hochschulort (West-/Ostdeutschland ) als auch der Hochschulort nach Bundesländern abgeleitet. |
| doNotDisplayThousandsSeperator | Nein | Wenn bei der Anzeige der Werte einer Variablen keine Tausendertrennzeichen angezeigt werden sollen, muss hier „true“ angezeigt werden (z. B. Jahreszahlen). Bleibt das Feld leer, wird dies als „false“ interpretiert, d.h. es werden Tausendertrennzeichen angezeigt. |
* Wenn eigene Konventionen verwendet werden, muss das Feld manuell ausgefüllt werden. Bei Verwendung von FDZ-eigenen Schemata kann dieses Feld auch leer gelassen werden.
| Tabellenblatt 2: relatedQuestions | ||
|---|---|---|
| Variablen, die mit mehreren Fragen verbunden sind, können mehrfach aufgeführt werden. Variablen, die keiner Frage (oder keinem Instrument) zugeordnet sind, müssen nicht eingetragen werden. | ||
| Es können mehrere verbundene Fragen eingetragen werden (= mehrere Zeilen, eine verbundene Frage pro Zeile) | ||
| Spaltenüberschrift | Muss ich das ausfüllen? | Was muss ich eintragen? |
| name | Ja | Variablenname |
| relatedQuestionStrings.de/.en | Nein | Text, der den Frageinhalt der Variable darstellt. Also Fragetext der dazugehörigen Frage plus evtl. weitere Ausführungen wie bspw. der Itemtext (bei Itembatterien) oder der Antworttext (bei Einfach- oder Mehrfachnennungen) wichtig: da diese auch in den Datensatzreport als „Fragetext“ ausgelesen werden, muss unbedingt auf eine korrekt Formatierung (Leerzeichen, Zeilenumnrüche etc.) geachtet werden. |
| questionNumber | Ja | Nummer der zur Variablen zugehörigen Frage im Fragebogen |
| instrumentNumber | Ja | Nummer des zur Variablen zugehörigen Fragebogens |
Dem Namen entsprechend wird aus den Informationen des zweiten Tabellenblatts die Verknüpfung zwischen einer Variablen und der dazugehörigen Frage aus dem Erhebungsinstrument erstellt. Für eine nachvollziehbare Dokumentation dieser Verbindung ist die Erstellung eines Variablenfragebogens sehr hilfreich. Aus diesem kann die Verknüpfung aus Variable und Frage problemlos abgelesen werden. Abb. 49 zeigt beispielhaft, dass den Variablen astu08a bis astu08e die Frage 1.8 zugeordnet ist.

Abb. 49 Ausschnitt aus dem Variablenfragebogen des Absolventenpanels 2005, erste Welle, Frage 1.8
Außer der/den Excel-Tabelle/n müssen Sie für jede Tabelle noch den zugehörigen Stata-Datensatz liefern, aus dem die Variablen stammen. Diese Dateien speichern Sie dann in dem Ordner, den das FDZ für Sie vorbereitet hat. Das FDZ greift daraufhin auf die Dateien zu, verarbeitet sie weiter und lädt die finalisierten Metadaten für die Variablenebene dann selbst ins MDM.
Erstellung der Variable-JSON Dateien¶
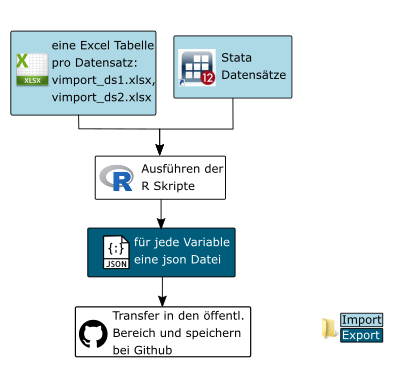
Die Erstellung der Variablen JSONs erfolgt komplett im geschützten Bereich. Benötigt werden pro Datensatz ein zugehöriger Stata-Datensatz und eine Exceltabelle. Die Exceltabelle (vimport_dsNR.xlsx) enthält die beiden Tabellenblätter variables und relatedQuestions. Pflichtspalten und zugehörige Ausfüllanweisungen werden im folgenden Abschnitt beschrieben.
Es ist erlaubt die Exceltabellen um weitere optionale Spalten zu erweitern, z.B. Varname_alt, Var_Erh, Var_Thema, Var_Nr, Var_Indiz, Var_g, Var_h, Var_x, Var_p, Var_v, Var_Zugang, Varlabel_alt, Varlabel_neu, On-Site, Remote-Desktop, Download-SUF, Download-CUF, AIP, SIP, delete, …
Momentan liegen die Import Dateien der Projekte, sowie die Skripte zur Erzeugung der JSONs im geschützten Bereich unter Q:Variablenexport. Der Aufbau der Ordnerstruktur ist wie folgt:
|--Variablenexport
|--Projekte
|--gra2005
|--variablesToJsons.bat
|--output
|--ds1
|--ds2
|--data-raw
|--stata
|--ds1.dta
|--ds2.dta
|--excel
|--vimport_ds1.xlsx
|--vimport_ds2.xlsx
|--conditions.xlsx
|--variable-generation_productive
|--variablesToJsons.bat.tmpl
Um json Dateien für ein neues Projekt zu generieren, muss zunächst ein Ordner für das neue Projekt angelegt werden und die oben gezeigt Ordnerstruktur aufgebaut werden. Im Ordner stata befinden sich die jeweiligen Stata Datensätze (ds1, ds2, ds3, …) und im Ordner excel die zugehörigen Exceltabellen mit den beiden Tabellenblättern variables und relatedQuestions (vimport_ds1.xlsx, vimport_ds2.xlsx, vimport_ds1.xlsx, …), sowie die Datei mit den missing conditions (conditions.xlsx). Zum Generieren der json Dateien das R-Skript variablesToJsons.bat.tmpl in den Projektordner kopieren, das .tmpl entfernen, die Datei anpassen und danach ausführen.
Es ist möglich die Missing Bedingungen für numerische und string Variablen in der datei conditions.xlsx anzupassen. Außerdem können in der batch-Datei Variablennamen angegeben werden, die im MDM keine Verteilung bekommen sollen. Dies sind z.B. id Variablen. Variablen mit accessway not-accessible müssen hier nicht eingetragen werden.
Missing Conditions
In der Exceltabelle conditions.xlsx können für numerische und string Variablen Missingbedingungen angegeben werden. Die Exceltabelle enthält die beiden Tabellenblättern missingConditionNumeric und missingConditionString. Es ist möglich für numerische und string Variablen jeweils mehrere Bedingungen anzugeben. Die Bedingungen werden mit ODER verknüpft. Das heißt, wenn eine der Bedingungen für einen Wert zutrifft, wird dieser Wert als Missing gewertet. Die verfügbaren Operatoren können in der Exceltabelle über ein Drop-Down Menü ausgewählt werden und sind im Tabellenblatt list of valid operators dokumentiert.
Ein Fehler der auftreten kann ist, dass im Stata-Datensatz nicht die richtige Sprache gewählt wurde. Ist das der Fall können nicht die richtigen Wertelabel zugeordnet werden.
Transfer in den öffentlichen Bereich Die Datensatzordner mit den json Dateien müssen noch in den öffentlichen Bereich transferiert werden. Da es nicht möglich ist, Ordner zu transferieren, werden die Ordner gezippt (7-Zip), transferiert und im öffentlichen Bereich wieder entpackt.
Die Variable-JSON Dateien müssen anschließend bei Github in das Repository projectid-metadata in den variables Ordner hochgeladen werden. Siehe z.B. http://github.com/dzhw/gra2005-metadata/ . Die Ordner werden anschließend auf Variablenebene ins MDM per Drag and Drop oder über den Plusbutton rechts unten hochgeladen.
Variables (Zofar)¶
Bei Onlinebefragungen mit ZOFAR können fragenbezogene Metadaten auf Variablenebene automatisch extrahiert werden. Eine .csv Tabelle die den Variablennamen, die Instrumentnummer, die Fragenummer und den relatedQuestionString (Fragetext + zugehöriger Variablentext) enthält, wird geliefert.
Der Prozess befindet sich im Aufbau…
| [1] | Metadaten auf Variablenebene sind erst ab der 2. Dokumentationsstufe gefordert. Die Erläuterungen zu den drei verschiedenen Dokumentationsstandards finden Sie in den Dokumenten „Anforderungen an Daten und Dokumentation im FDZ des DZHW“. |
| [2] | (1, 2) Nur in der Dokumentationsstufe 3 gefordert. Die Erläuterungen zu den drei verschiedenen Dokumentationsstandards finden Sie in den Dokumenten „Anforderungen an Daten und Dokumentation im FDZ des DZHW“. |